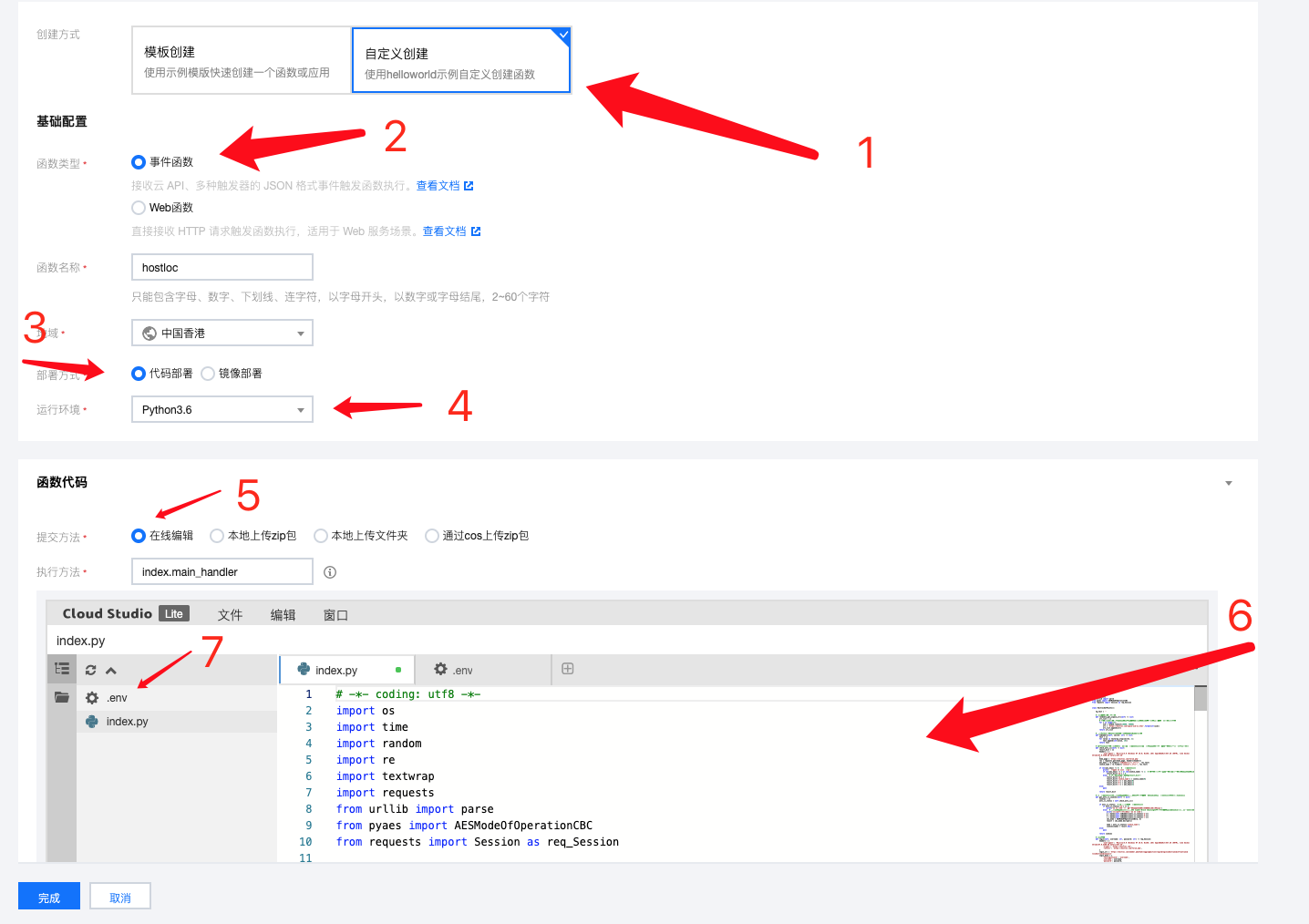
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
| # -*- coding: utf8 -*-
import os
import time
import random
import re
import textwrap
import requests
from urllib import parse
from pyaes import AESModeOfOperationCBC
from requests import Session as req_Session
class HostlocGetPoints():
tg_text = ''
# 随机生成用户空间链接
def randomly_gen_uspace_url(self) -> list:
url_list = []
# 访问小黑屋用户空间不会获得积分、生成的随机数可能会重复,这里多生成几个链接用作冗余
for i in range(13):
uid = random.randint(10000, 50000)
url = 'https://hostloc.com/space-uid-{}.html'.format(str(uid))
url_list.append(url)
return url_list
# 使用Python实现防CC验证页面中JS写的的toNumbers函数
def toNumbers(self, secret: str) -> list:
text = []
for value in textwrap.wrap(secret, 2):
text.append(int(value, 16))
return text
# 不带Cookies访问论坛首页,检查是否开启了防CC机制,将开启状态、AES计算所需的参数全部放在一个字典中返回
def check_anti_cc(self) -> dict:
result_dict = {}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
home_page = 'https://hostloc.com/forum.php'
res = requests.get(home_page, headers=headers)
aes_keys = re.findall('toNumbers\("(.*?)"\)', res.text)
cookie_name = re.findall('cookie="(.*?)="', res.text)
if len(aes_keys) != 0: # 开启了防CC机制
print('检测到防 CC 机制开启!')
if len(aes_keys) != 3 or len(cookie_name) != 1: # 正则表达式匹配到了参数,但是参数个数不对(不正常的情况)
result_dict['ok'] = 0
else: # 匹配正常时将参数存到result_dict中
result_dict['ok'] = 1
result_dict['cookie_name'] = cookie_name[0]
result_dict['a'] = aes_keys[0]
result_dict['b'] = aes_keys[1]
result_dict['c'] = aes_keys[2]
else:
pass
return result_dict
# 在开启了防CC机制时使用获取到的数据进行AES解密计算生成一条Cookie(未开启防CC机制时返回空Cookies)
def gen_anti_cc_cookies(self) -> dict:
cookies = {}
anti_cc_status = self.check_anti_cc()
if anti_cc_status: # 不为空,代表开启了防CC机制
if anti_cc_status['ok'] == 0:
print('防 CC 验证过程所需参数不符合要求,页面可能存在错误!')
else: # 使用获取到的三个值进行AES Cipher-Block Chaining解密计算以生成特定的Cookie值用于通过防CC验证
print('自动模拟计算尝试通过防 CC 验证')
a = bytes(self.toNumbers(anti_cc_status['a']))
b = bytes(self.toNumbers(anti_cc_status['b']))
c = bytes(self.toNumbers(anti_cc_status['c']))
cbc_mode = AESModeOfOperationCBC(a, b)
result = cbc_mode.decrypt(c)
name = anti_cc_status['cookie_name']
cookies[name] = result.hex()
else:
pass
return cookies
# 登录帐户
def login(self, username: str, password: str) -> req_Session:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'origin': 'https://hostloc.com',
'referer': 'https://hostloc.com/forum.php',
}
login_url = 'https://hostloc.com/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1'
login_data = {
'fastloginfield': 'username',
'username': username,
'password': password,
'quickforward': 'yes',
'handlekey': 'ls',
}
s = req_Session()
s.headers.update(headers)
s.cookies.update(self.gen_anti_cc_cookies())
res = s.post(url=login_url, data=login_data)
res.raise_for_status()
return s
# 通过抓取用户设置页面的标题检查是否登录成功
def check_login_status(self, s: req_Session, number_c: int) -> bool:
test_url = 'https://hostloc.com/home.php?mod=spacecp'
res = s.get(test_url)
res.raise_for_status()
res.encoding = 'utf-8'
test_title = re.findall("<title>(.*?)<\/title>", res.text)
if len(test_title) != 0: # 确保正则匹配到了内容,防止出现数组索引越界的情况
if test_title[0] != '个人资料 - 全球主机交流论坛 - Powered by Discuz!':
self.tg_text = self.tg_text + '\n第{}个帐户登录失败!\n'.format(number_c)
print('第{}个帐户登录失败!'.format(number_c))
return False
else:
self.tg_text = self.tg_text + '\n第{}个帐户登录成功!\n'.format(number_c)
print('第{}个帐户登录成功!'.format(number_c))
# 获取并打印当前账户名
test_url = 'https://hostloc.com/forum.php'
res = s.get(test_url)
res.raise_for_status()
res.encoding = 'utf-8'
name = re.findall('title="访问我的空间">([\s\S]{,20})</a>', res.text)[0]
self.tg_text = self.tg_text + '当前账户:' + name + '\n'
print('当前账户:' + name)
return True
else:
self.tg_text = self.tg_text + '无法在用户设置页面找到标题,该页面存在错误或被防 CC 机制拦截!\n'
print('无法在用户设置页面找到标题,该页面存在错误或被防 CC 机制拦截!')
return False
# 抓取并打印输出帐户当前积分
def print_current_points(self, s: req_Session):
test_url = 'https://hostloc.com/forum.php'
res = s.get(test_url)
res.raise_for_status()
res.encoding = 'utf-8'
points = re.findall("积分: (\d+)", res.text)
if len(points) != 0: # 确保正则匹配到了内容,防止出现数组索引越界的情况
self.tg_text = self.tg_text + '帐户当前积分:' + points[0] +'\n'
print('帐户当前积分:' + points[0])
else:
self.tg_text = self.tg_text + '无法获取帐户积分,可能页面存在错误或者未登录!' + '\n'
print('无法获取帐户积分,可能页面存在错误或者未登录!')
time.sleep(5)
# 依次访问随机生成的用户空间链接获取积分
def get_points(self, s: req_Session, number_c: int):
success = 0
fail = 0
if self.check_login_status(s, number_c):
self.print_current_points(s) # 打印帐户当前积分
url_list = self.randomly_gen_uspace_url()
# 依次访问用户空间链接获取积分,出现错误时不中断程序继续尝试访问下一个链接
for i in range(len(url_list)):
url = url_list[i]
try:
res = s.get(url)
res.raise_for_status()
print('第', i + 1, '个用户空间链接访问成功')
success += 1
time.sleep(5) # 每访问一个链接后休眠5秒,以避免触发论坛的防CC机制
except Exception as e:
fail += 1
print('链接访问异常:' + str(e))
continue
self.tg_text = self.tg_text + '用户空间成功访问{}个,访问失败{}个\n'.format(success, fail)
self.print_current_points(s) # 再次打印帐户当前积分
else:
self.tg_text = self.tg_text + '请检查你的帐户是否正确!\n'
print('请检查你的帐户是否正确!')
# 打印输出当前ip地址
def print_my_ip(self):
api_url = 'https://api.ipify.org/'
try:
res = requests.get(url=api_url)
res.raise_for_status()
res.encoding = 'utf-8'
self.tg_text = self.tg_text + '当前使用 ip 地址:' + res.text.replace('.', ',') + '\n'
print('当前使用 ip 地址:' + res.text)
except Exception as e:
self.tg_text = self.tg_text + '获取当前 ip 地址失败:' + str(e) + '\n'
print('获取当前 ip 地址失败:' + str(e))
# TG推送
def post(self, bot_api, chat_id, text):
print('开始推送')
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36'}
text = parse.quote(text)
# 修改为自己的bot api token
post_url = 'https://api.telegram.org/bot{}/sendMessage' \
'?parse_mode=MarkdownV2&chat_id={}&text={}'.format(bot_api, chat_id, text)
try:
requests.get(post_url, headers=headers)
print('推送成功')
except Exception:
print("推送失败")
time.sleep(3)
# 避免推送死循环
try:
requests.get(post_url, headers=headers)
except Exception:
pass
def hostloc_get_points(self, usernames, passwords, bot_api, chat_id,):
# 分割用户名和密码为列表
user_list = usernames.split(',')
passwd_list = passwords.split(',')
if not usernames or not passwords:
self.tg_text = self.tg_text + '未检测到用户名或密码,请检查环境变量是否设置正确!\n'
print('未检测到用户名或密码,请检查环境变量是否设置正确!')
elif len(user_list) != len(passwd_list):
self.tg_text = self.tg_text + '用户名与密码个数不匹配,请检查环境变量设置是否错漏!\n'
print('用户名与密码个数不匹配,请检查环境变量设置是否错漏!')
else:
self.print_my_ip()
self.tg_text = self.tg_text + '共检测到{}个帐户,开始获取积分\n'.format(len(user_list))
print('共检测到', len(user_list), '个帐户,开始获取积分')
print('*' * 30)
# 依次登录帐户获取积分,出现错误时不中断程序继续尝试下一个帐户
for i in range(len(user_list)):
try:
s = self.login(user_list[i], passwd_list[i])
self.get_points(s, i + 1)
print('*' * 30)
except Exception as e:
self.tg_text = self.tg_text + '程序执行异常:'
print('程序执行异常:' + str(e))
print('*' * 30)
continue
self.tg_text = self.tg_text + '\n程序执行完毕,获取积分过程结束'
print('程序执行完毕,获取积分过程结束')
# print(self.tg_text)
self.post(bot_api, chat_id, self.tg_text)
if __name__ == '__main__':
usernames = os.environ['HOSTLOC_USERNAME']
passwords = os.environ['HOSTLOC_PASSWORD']
bot_api = os.environ['BOT_API']
chat_id = os.environ['CHAT_ID']
h = HostlocGetPoints()
h.hostloc_get_points(usernames, passwords, bot_api, chat_id)
|